
With immuno-oncology assets progressing in the clinic, a growing biotechnology company we work with faces an increasingly common challenge:
Their trials are generating large datasets across a wide range of assay modalities (Figure 1), but the data remains siloed.
In addition to clinical data coming from the clinical research organization (CRO), the velocity of data coming from an assay services laboratory continuously delivering biomarker data from flow cytometry, immunohistochemistry, and genomics platforms quickly becomes overwhelming. Still another, separate data stream comes from a specialty laboratory delivering T-cell receptor (TCR) profiling data.
Deep layers of associated (but disconnected) data
Compounding the challenge, results data delivered by both laboratories is associated with contextual and ancillary information, like images, gating information, and advanced annotations. But these associated files are housed separately from the results data, making it labor-intensive to monitor and confirm data quality during analysis.
Since the start of the trial, translational research teams have been challenged to:
- Link data across modalities at all levels – sample, patient, cohort, biomarker-defined subgroup
- Reduce friction caused by ongoing (reactive) integration and QC, as additional data is continuously being generated
- Centralize reportables and ancillary data for timely access to inform on-study decision-making
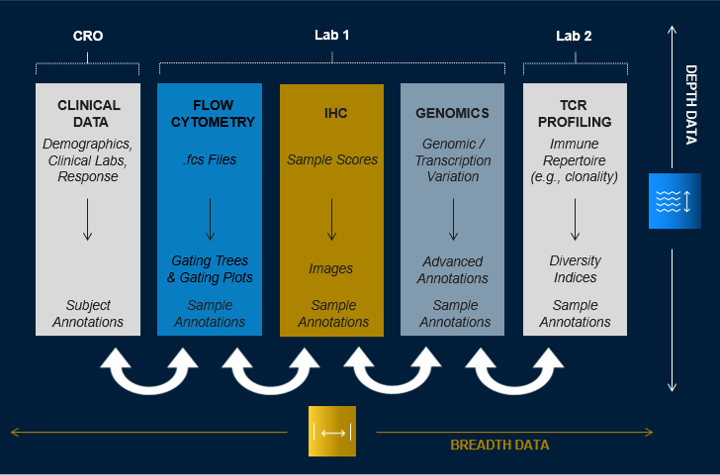
Figure 1. Breadth and Depth of Data Generated by Biomarker-informed Clinical Programs. Translational teams are interacting with a diverse breadth of data sources to gather all the reportables per patient and by sampling time point, including clinical and biomarker assay data, protocols, consents, sample inventory data. They are also interacting with the depth of those data, from underlying raw data to ancillary files.
Lacking the centralized infrastructure necessary to answer questions that have become critical in biomarker guided drug development, the translational researchers have had to conduct intensely manual efforts to prepare data for targeted analyses – which quickly becomes overwhelming.
They have also called upon experts specializing in each assay technique to clean and manage datasets. Even then, the translational researchers were unable to consistently execute the optimal analyses, since they lacked direct access to the necessary data.
The Solution: Sponsor-Centric Agentic Platform
Creating meaningful visibility across this network of data streams required not only centralizing information and data, but also effectively harmonizing and integrating this historically siloed information.
The team approached QuartzBio to help them implement a sponsor-centric platform to centralize data from the various sources and systems.
Centralizing the diversity and layers of data is an important first step to streamlining access and usability of key data elements. It is also necessary to maintain visibility into data availability throughout a study and to streamline access to the diversity of information coming from vendors.
Outcomes
Through deep harmonization of data streams using the QuartzBio Platform and Biomarker Intelligence Solution, the translational research team has been able to present historically disconnected assay formats together, in flexible dashboards with visualization and analytical tools – on-study and normalized across studies.
Given the breadth of labs providing data (and the varied sophistication of their IT infrastructure), the platform was designed to accommodate a range of file formats, secure data uploads, FTP-driven transfers, and API integration.
Importantly, integrating the breadth of data did not require the specialty labs to adhere to new data delivery formats, which could have delayed progress. QuartzBio’s approach utilizes workflows that are flexible and can accommodate any data type – and provide ongoing visibility into quality control (QC). For example, the platform extracts data from PDF documents before integrating it with other sources.
Trial information, such as the protocol, enrollment trackers, and key lab documentation was linked first, supporting forward-looking projections of future data availability, and highlighting gaps in ongoing data generation.
For assay results data, continuously being delivered throughout studies, the platform provides quality control and mapping to a common data dictionary, enabling meaningful connections between different assay technologies and clinical metadata. This requires configuration and deployment and monitoring of assay-specific pipelines.